The Slow Client Problem
The Slow Client Problem and why I had never run into it
When I first started playing with Node.js, I quickly found several mentions of the so called Slow Client Problem. This problem may arise anytime you’re writing on some stream, if the production of data is faster than the consumption.
The typical case is a socket where one end can not read as fast as the other end can write. This could happen, for instance, to a HTTP server sending a local file to someone with a slow connection. For the server, reading from the file will probably be quite fast, while writing to the network may be slow. But the problem may happen locally too if, for instance, you’re generating random data very quickly and writing them to a local file that can’t keep up with the pace.
What happens then is that memory consumption grows, since the server buffers all data while it waits for the client to consume it. It would take a handful of slow clients downloading big files to fill up a system’s memory in no time.
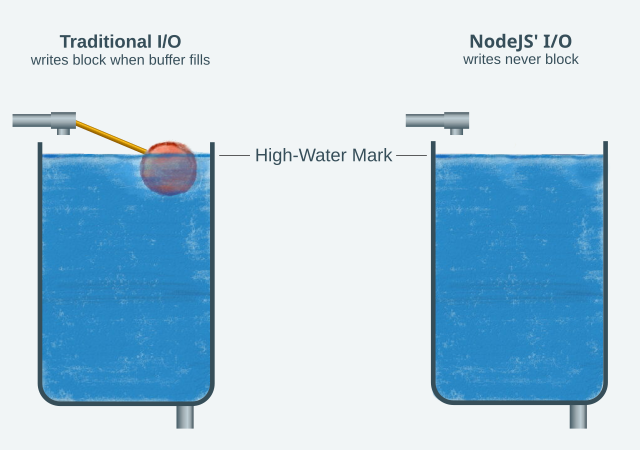
Traditional I/O is like a water tank with a ballcock.
What struck me, though, is that I had never run into that problem before, and I have built my good share of servers and tunnels that moved all kinds of data around. Heck, that was a question that I posed regularly to my students in my Operating Systems course: how is the read/write speed of both ends synchronized when using sockets & pipes?
The difference is Node’s highly asynchronous design.
Traditionally, the speed of both ends is quickly balanced by the fact that read and write are blocking syscalls. It’s just like the ballcock system at the left in the image above. The system buffers some of the write calls, but the amount of memory reserved for that (the water tank) is relatively small and when it fills, the next write call blocks. In the case of read, if there is nothing to be read, and the other side hasn’t closed yet, the call also blocks.
With those rules, if a program wrote too quickly, it would block until the other side read some of the data. And if the reader was the faster one, it would block frequently, waiting for the writer to write something. A simple, but not fully asynchronous way to implement a TCP tunnel in Python looks like this:
...
# Core of a simple, but not fully asynchronous TCP tunnel
while True:
r,w,e = select(read_fds, [], error_fds)
for fd in r:
buf = fd.read(buffer_size)
# otherfd is the peer of fd in the tunnel
otherfd.write(buf) # <=== potentially blocking
...
...This tunnel uses select to wait for data to arrive and then immediately sends it to the corresponding descriptor. This is the way I had usually built my tunnels. Note that I pass [] as the second argument of select, so I’m not watching for ready-to-write conditions.
That makes the implementation simpler, and performance is decent. But the program blocks frequently on otherfd.write. And when it’s blocked there, it can’t react to data coming from any other client. If that takes long because the client is slow, the entire server suffers.
In Node.js things are different. Node.js is a platform devoted to reduce blocking to a minimum. For almost any operation, even opening a file, you don’t get a result when the call returns. Instead, you must provide a function object that Node will call when the operation is finished. Javascript’s powerful support for function objects, and its lack of a previously established I/O library, helped Node achieve that elegantly.
The upside of this design is that it allows Node to handle hundreds of concurrent I/O operations in a single thread. Even when the Python code above would be blocked in otherfd.write(buf), an equivalent Node code would be free to accept new connections or read for any file descriptor that’s ready.
The downside is that the syncronization of speeds, which depends on the blocking nature of read and write, breaks somewhat. Reading is not a big deal, because your code, given as a callback, is only executed when there’s data.
But if you do this:
read_stream.on('data', (data) => {
write_stream.write(data)
});you may run into problems.
Node will never block at write_stream.write(data), because blocking is against its nature. It will buffer data in memory and will instruct the system to write it to write_stream’s underlying file descriptor. If the other side of write_stream reads too slowly, Node’s buffer for it will grow on and on. And that’s the Slow Client Problem.
Node gives us a few tools to address this:
- First, the
writemethod of a writable streams returns true or false to indicate whether Node has begun buffering internally. That can be used to decide to stop writing for a while. - Second, writable streams emit a
'drain'event to indicate that Node already handled all pending writes. That’s the right time to resume writing. - Third and last: readable streams have a
pipe(writable)method that does 1 and 2 automatically with the given writable stream.
The water tank analogy is visible in Node’s API. The drain method name evidences it, as does the fact that streams have a property called precisely highWaterMark that’s used to decide whether write returns true or false.
Conclusion
Node’s highly asynchronous design is excellent for handling a large number of concurrent I/O operations. It however, comes with some caveats, like having to be careful when writing a lot of data to a potentially slow client, which could consume a lot of memory. That problem was non-existent when using traditional blocking read and write calls in other programming languages. Node, luckily, gives us very cool tools to address it, like pipe, when we want the whole thing to work automatically, and write and 'drain' when we want to control the data as it passes through.